


How to Structure Your Data Science Teams
How to Structure Your Data Science Teams
Do You Know How to Structure Your Team?

Organization is the Foundation of Productive Teams

Introduction
Good team organization allows:
Flexibility
Efficiency
Morale and Cohesion
Effectiveness
Collaboration
In this article, I wanted to talk about the three types of data teams that organizations can use and how roles play a part in them.
I’ve worked in different types of data teams as a consultant and individual contributor, and team structure and the right roles were critical in many of the high performing teams that I’ve worked with. It was key to building their confidence to take on challenging tasks and turning them around quickly.
Organization and team structure is absolutely crucial in the long run. Planning and the cost of this organization may not have immediate results, but in the long run, the benefits are exponential.
With that said? Let's dive right into it!
Benefits of Team Structure

The right team structure allows the right allocation of resources, while preventing team and individual contributor burnout.
A good data science team has the right roles within the team, and right place in an organization that meets larger business needs.
A properly structured data science team, with the right roles, allows flexibility and mobility. Flexibility lets teams pivot between projects, ad hoc requests, and emergencies. Mobility allows quickly assessing, acting, and resolving problems.
A proper team structure combined with excellent leadership lets a team not only deliver, but exponentially deliver business value.
But how they deliver is very dependent on where they sit within the larger organization. This is where types of teams and the right roles within them matter.
Roles Inside Data Teams
So what are the typical roles you find in a data science team? The normal roles are:
Data Analyst
Data Engineer
Data Scientist
ML Engineer
Manager
Other Data Roles
Roles can have overlapping responsibilities which depends on business need, workload, or company culture. They are usually broken up into a single team or team with squads underneath them.
Roles in Teams
Teams are usually run directly by a manager, which can be broken up into one or more squads.
Team composition will be different depending on the need, specialization, and focus of the organization. Roles in teams and the squads underneath the teams may be mixed. Some teams will be composed completely of one role, while other teams may have two or more roles in them.
For example? Reporting teams would be mostly data analysts. A ML modeling team might be a data scientist and a ML engineer. While a deployment focused team may have only ML engineers.
Roles in Squads
Squads exist under individual teams. If a squad exists, it is usually run by a lead, such as a Senior Data Scientist. At the smallest, they are two people: a senior and a junior. At their largest, they may be four or more people.
Each squad focuses a specific feature that the larger team is working on. The squad lead focuses on assessing progress, quality control, and mentoring junior members.
Types of Teams
Centralized Team
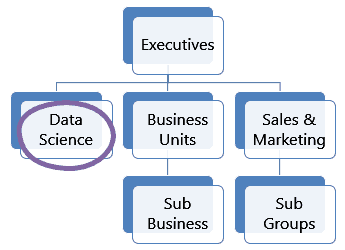
The centralized team is independent of other groups in the organization. Usually, it sits alone. These teams assist other business units such as marketing, sales, finance, etc. The centralized team is responsible for all data science work: engineering, analytics, and machine learning.
Since they are centralized, they are familiar with the use cases, data science needs, and data relationships between departments. They take on the responsibility of analyzing, engineering, and visualizing solutions for business units.
Centralized teams have a great knowledge store. However, since they are taking on much of the analytics and data science work there is a possibility for them to be overworked.
The centralized team model is common in many industries since it’s easy to set up with little planning and effort. It is often the starting team structure for new companies getting into data science.
The ability for the team to be effective can depend on the size. This structure is the most effective in smaller organizations since the workload and communications are easier. In larger organizations it can be cumbersome due to the workload, communication, and expectations it must take on.
Advantages
Common knowledge and best practices. Easier to share it with the larger organization.
Centralized. Tasks, ad-hoc requests, and projects are unlikely to be duplicated, saving time and money.
Specialization. Specialized contributors can be moved around as needed, and be placed in the projects were they can maximize their talents. This is also useful, since it helps build their morale and ownership
Disadvantages
Lack of redundancy. If the central unit is overloaded, lacks resources or staff, or has too much on its plate, there is no back up.
Communication. Each business unit has to submit tickets to a central team. The tickets must be scoped before the team works on a task or project.
Prioritization. The central team handles all the requests for the business units — analysis, visualizations, data pipeline building, etc. Certain tasks may be prioritized for certain business units. Which can back up work for others.
Decentralized Team
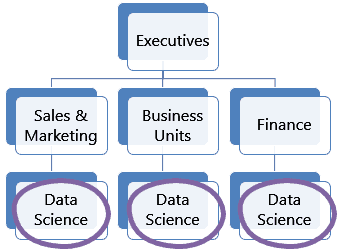
A decentralized team exists within a business unit. Each department has its own data science team composed of engineers, analysts, and data scientists. These teams only work with their business units — they specialize their knowledge and skills.
This allows them to focus on one type of work while developing deep domain knowledge. All work is focused towards building tools, models, and engineering for the business units. This helps when setting KPIs, definitions of data quality, and finding use cases.
Unlike the centralized team, they may have a quicker turn around time, since they aren’t responsible for insights for all business units.
Decentralized teams are more common in medium to larger size companies, usually because of the volume of data and needs that require specialization.
Advantages
Specialization. They’re within the business unit and hence can work on that unit’s priorities.
Quick Turnarounds. They can deliver results and quick wins, especially in the first few projects because they are aligned with the end-users
Domain Knowledge. Teams gain domain knowledge as they work within the unit.
Disadvantages
Siloed. Talent and specialists are limited to the teams they are assigned. Best practices rarely go outside business units, since there isn’t much interaction between teams.
Conflicting Definitions. Different teams may use the same KPIs and business objects but calculate them differently. This can lead to confusion on a higher level.
Support. Support for larger initiatives can be limited to within the business unit, due to specialization. This makes it difficult for teams to work and coordinate across units.
Hub and Spoke Team
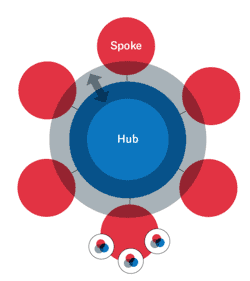
The Hub and Spoke Team is usually found in organizations with 500 or more people, with distinct business units.
This is due to the cost, time, and coordination required to build it. Processes, responsibilities, quality, and data ownership must be very well defined for this team structure to work effectively. This organization is composed of two sections: the hub and the spoke.
The hub focuses on strategic priorities. This includes:
Strategic analysis
Building data building infrastructure,
Documenting organization-wide data quality, governance, and process standards.
It is also responsible for building and deploying ML models. Its main role is to do the heavily data science lifting — enabling the spokes. The hub usually has a mixture of data analysts, data engineers, data scientists, and machine learning engineers.
The hub enables the spoke, but does not set direction or policy. Its main focus is enabling the spokes to perform their work, while building the infrastructure and tools to support business units. It also serves as a mediator for data definitions and as a resource for initiatives.
The spoke is the individual business unit. These units are marketing, finance, sales, etc. Each spoke focuses on their specialization. Analysis, visualization, and business intelligence are owned by each business unit in the spoke. These units have their own analysts that work separately from the data analysts in the hub.
Conclusion
In this article, we have learned how teams are organized, including three main systems: centralized, decentralized, and hub and spoke data science teams. We also learned how roles exist within these teams.
Team structure is always a work in progress. It takes planning, time, and deliberate effort to be effective. It takes selecting the right roles for the team to maximize effectiveness. An organization needs to discover what works best for it. This depends largely on organizational data culture, infrastructure, and your data maturity.
If you enjoyed this article, you might also enjoy my other articles at Heartbeat and beyond:
Enhancing MLflow with Comet
Got existing MLflow experiment runs? Comet can help!heartbeat.comet.ml
Dealing With Data Science Overload
4 Ways to Keep Yourself Going…when it feels like too much.medium.com